|
| Introduction | Performance Bottlenecks | Benchmarks | Architectures | APIs | Links |
For an updated version of this article check out the March/April 2001 edition of pro-E magazine.
| Introduction |
First of all, let me establish the general topic of discussion as real time graphics rendering. That means drawing a desktop GUI, playing a game or real time simulation or animation. Other topics such as raytracing, or image processing are really not what this page is about.
Graphics accelerators are coprocessors that reside in your computer that assist in drawing graphics. GUI's such as Windows take advantage of these if a "display driver" is available to perform graphics more efficiently than purely software based algorithms. If you bought an Intel based PC in the last couple years, chances are you have a graphics accelerator in it.
A graphics accelerator assists graphics rendering by supplying primitives that it can execute concurrently with and more efficiently than the x86 CPU. One reason the accelerator can be more efficient than the CPU is because it lives closer to the graphics memory; it does not have to transfer raw pixel data over a slow (relative to the speed of the graphics RAM) general BUS and chipset. But the main reason a graphics accelerator improves overall graphics performance is because it executes concurrently with the CPU. This means that while the CPU is calculating the coordinates for the next set of graphics commands to issue, the graphics accelerator can be busy filling in the polygons for the current set of graphics commands. This dividing up of computation is often referred to as load balancing.
Operating Systems
Note that the Apple Macintosh's older built-in graphics API does not allow for this sort of concurrent graphics operation. The reason is that the frame buffer was not abstracted in any way. Popular applications such as Adobe's Illustrator and type manager access the frame buffer directly, without any access arbitration. While apps that use the 32-bit QuickDraw API can leverage acceleration, the degree to which any serious applications on the Mac leveraged this is a completely unknown quantity.
However, in an unprecedented move to challenge the Wintel duopoly Apple recently made an astounding move. They have decided to adopt the OpenGL standard! I don't know the details (I think its a Rhapsody/OS X only thing) but the upshot is that this page also applies to the next generation of OS's from Apple that will include OpenGL support.
My most up to date knowledge is that Linux and BeOS also have highly accelerated OpenGL implementations (but only on some graphics cards.)
But the largest deployed base of accelerated graphics solution with the richest variety and highest performance is by far the Windows platform (something that should make executives at SGI feel like complete dufuses.) So while the discussion applies to high performance graphics architectures in general, the background is rooted in the Windows graphics architecture.
Below is a block diagram explaining a modern graphics architecture.
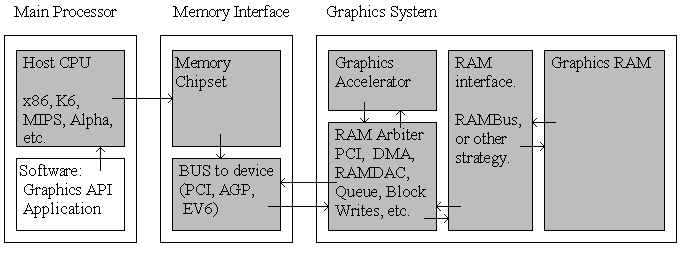
A modern graphics accelerator these days is measured by screen resolution and
refresh rate capabilities, TV-out compatibility, video playback, image quality
and 2D GUI primitive support. But the driving force of recent times is their
3D capabilities. 2D-only cards are no longer being taken seriously. The
topics of 2D and video/MPEG is interesting but I will not concentrate too much
discussion on them.
| Performance Bottlenecks |
For applications wishing to maximize graphics performance, the following are the most encountered bottlenecks.
- graphics memory bandwidth
- communication between host and graphics accelerator
- features and host feature emulation
- monitor refresh
A funny thing, is that it has been widely theorized that memory upload performance (from host to graphics memory) was also a serious bottleneck. One which Intel has supposedly "solved" via their AGP technology. However, empirical evidence suggests that AGP enabled graphics cards do not perform any better as a result of their AGP interface, in real world applications.
Graphics Memory Bandwidth
The biggest bottleneck in graphics performance is the speed at which the accelerator can output its results to memory. However ordinary memory technologies are fairly well established/understood and hold very little promise for great improvements beyond the run of the mill SDRAM or RDRAM. In the past, accelerator companies such as ATI experimented with VRAM, a kind of RAM technology that could allow multiple accesses per cycle (one for video refresh, and one for accelerator output). The result was an expensive, clock rate limiting solution, that actually did not perform any faster than comparable DRAM solutions. Similarly, the extra cost of RDRAM is not justified in terms of actual performance returns. (The MPACT media processor, Cirrus Laguna, and several SGI systems including the Nintendo 64 are based on RAMBUS.)
So how is it that graphics companies can claim extraordinarily increasing bandwidth on a regular basis? Simple, the RAM is partitioned over multiple BUSes. In Chromatic's MPACT 2 architecture, the RAMBUS was splined twice, and identical memory requests were sent over both BUSes to two independent RDRAMs (you can just stare at the boards to see this). The RAM arbitrator would then combine the results into double sized data, by interleaving the physical memory bytes. The internal data paths did not need to be increased, since the arbiter could simply buffer the access. Instead, the clock rate of the processor itself was doubled relative to the memory so that it could perform the memory requests at twice the ordinary rate. (Memory latency is not changed in absolute performance, of course.) Ordinarily this approach has a high cost due to the larger pin count, however RAMBUS is a low pin count solution.
Another strategy employed by S3, 3DFX, and others is to simply slice the memory in large sequential banks. Ideally this can reach performance levels equal to that of splining so long as the memory objects in a given rendering operation are partitioned over these seperate banks. But this arbitrary partitioning leads either to limitations in total memory usage for each type of memory object on non-optimal bandwidth usage in many situations. It also leads to a lot of extra work in the software to try to exploit multi-bank usage.
These companies certainly didn't pioneer this technique. Matrox has been using the idea for some time in their Millenium 2D accelerator (I don't know if Matrox uses banking or splining, but I tend to think it must be banking since they seemed to have line width granularity limitations in some of their parts). In fact, any graphics accelerator that claims to have memory bandwidth that exceeds physical RAM limitations is using a multiple spline or bank technique such as this one. These days, that would be just about every graphics accelerator company.
As a side effect, this usually affects board design. Graphics RAM will be broken down over multiple RAM chips; i.e., you can actually see these things on your physical graphics board. This slightly increases the complexity of the board (and therefore the testing of it), but delivers a lot more performance.
The BitBoys (architects of the Pyramid 3D and the proposed Glaze3D graphics accelerator) proposed a novell idea to improve memory bandwidth. They are simply embedding a eDRAM and splining the on chip (and therefore much cheaper) bus up to 512 bits. They claim a 9.6 GB/s bandwidth which is about 3 times the bandwidth of conventional 128 bit @ 200Mhz solutions. Given the kind of technology required for this, it would seem that the BitBoys would have leap frogged the rest of the industry. However, their part has not materialized and they appear to have completely backpedalled on their marketing campaign. Hardware designers who have looked at their claims have suggested that the RAM manufacturing process that Infineon uses for the eDRAM is totally unsuitable for the logic gates required by the accelerator core.
In the specific area of 3D, texture caching, texture compression, and in fact, MIP mapping all aid in the area of memory bandwidth as well.
Another important issue in combatting the problem of memory bandwidth is to increase the efficiency of memory accesses via tiled addressing. This is where, rather than addressing the screen in simple increasing addresses with respect to lexical (y,x) ordering, the screen is broken into rectangular tiles. This is benenficial because memory references that are close to each other will tend to have higher performance than memory accesses that are spread apart (even fundamental memory chips use banking-like techniques to address their memory, to take advantage of the fact that access tend to be sequential.) Graphics primitives tend to have cartesian locality, as opposed to lexical (y,x) locality.
This technique is usually transparent to software. Hardware in the graphics ram arbitrator will typically translate addresses on the fly to generate a virtual linear addressing scheme. (The MPACT used this for 2D rendering, PowerVR uses it, Glaze3D was supposed to use it for 3D rendering.)
Texture and pixel caches also typically have rectangular structure, since access redundancy of the texture cache is not unidirectional. (I don't know all the details about the specific implementations of texture caches on various graphics cards, but you can imagine that they can, and ideally do have associativity levels just like CPU caches do.)
Host, accelerator communication
Roughly speaking, operations are communicateed from the host to the accelerator through some sort of command queue (or FIFO). The host graphics API (such as GDI, Direct Draw/3D, X or Open GL) are decomposed to these accelerator specific commands. These commands are then executed by the graphics accelerator then dequeued by the graphics accelerator in oldest first order. Writing to and arbitration of the graphics queue usually involves writes and reads to memory mapped graphics register locations, or I/O ports. However, writes to ordinary system memory and graphics based DMA strategies are also possible (I believe that nVidia, 3DLabs and possibly Matrox do this.)
One of the bottlenecks of the earlier graphics accelerators was that the queue would often be too small (typically 16 entries, as is the case of the original ATI Mach 64) to give the host and the graphics accelerator sufficient opportunity for parallelism. So, the host driver would commonly be stalled waiting for the queue to free up enough space for the next operation. In modern graphics accelerators, in one way or another, the queue has been significantly expanded usually to sizes usually above 512 entries. While a register window retained a small queue, a portion of the graphics memory would be used as a spill queue; essentially as an extension to the register window queue (I believe S3 does this.)
Another trick that some accelerators do to improve queue access performance was to memory map the queue to contiguous sequential addresses, so that the PCI bursting capabilities, of the host chipset would be used. (Both the MPACT and 3DFX accelerators do this.)
Triangle culling is also becoming a more and more important feature as well. There is a difficult debate as to whether culling should be performed on the host to reduce PCI bandwidth or in the video card where the culling operation itself can be performed most cheaply. The problem is that some software does the culling by itself (thus not needing any culling help from the video driver or the video card.) The reason for this is that some software carries more complicated attributes with its rendering objects -- hence up front clipping is beneficial to software based calculation reduction. The reason this is bad is that graphics solutions which are written conservatively will always perform some manner of backface culling themselves thus resulting in double-culling. Exposing some sort of "don't cull these before rendering" switch would probably be useful. (Hello Microsoft? Anyone listening?)
I believe nVidia has declared their intention on this issue: rely on the AGP bus' higher throughput (which is not a bottleneck) and just send everything, culling only in the accelerator.
Ordinarily the graphics accelerator is coupled with a fast (enough, given PCI BUS limits) frame buffer, so that if need be, the CPU can update the graphics memory instead of, or along with the graphics accelerator. Some cards such as the TSENG ET6000 actually maintained a cache between their frame buffer and the PCI BUS, so that host based accesses would have the minimum possible latency. (This would be part of the RAM Arbiter of the Graphics System) However as no actual parallelism is exploited (which is key to achieving the best possible performance with a graphics accelerator), it should not surprise anyone that the ET6000 was not a top notch performer.
As to the idea of simultaneous host and accelerator access to graphics memory, this is a rarely employed technique because it requires an advanced arbitration system which can isolate subregions of graphics RAM with respect to pending accelerator operations. The Chromatic MPACT media processor, in fact, has such an arbitration feature, which is very helpful in enhancing Windows DIB performance (these are 2D bitmap data structures that desktop application might use.) The MPACT has design issues that hampers it with respect to 3D performance, however, the MPACT media processor's software was assuredly the most parallel implementation of its time.
The common implementation of nearly all graphics accelerators when there is a requirement to read or write from the host to graphics memory is to wait until all pending graphics operations are done and the command queue has been emptied first. Under these situations, the cost of writing to the graphics memory also incurrs an additional penalty equal to the average total latency of graphics operation between host memory accesses. I.e., it sucks dead wookies. Most graphics vendors have concluded that decreasing operation latency is the only solution, but I do not agree.
The truth is, that a complex multiple access arbitration scheme does not actually require that much complex hardware support. It can be done with a simple "operation counter" scheme. Basically every time a graphics operation is completed, the operation counter (a memory mapped register, or simply a value in graphics memory) should increase. Then the software drivers should store a copy of what the operation counter will eventually be (i.e., shadow the graphics side counter with a host side counter) equal to once that operation is complete to a tag associated to the memory object (surface, front/back buffer buffer, or device bitmap in the Windows world) being operated on. Then with a combination of the right counter comparisons and queue size bounding to avoid counter wrap around conditions, you can know when the accelerator has no live pending operations on a given memory object. (This requires very stable hardware and software to avoid fatal hangs due to any sort of graphics memory corruption.)
The reason why it works is that it trades off host latency for graphics memory bandwidth. In a typical situation, many accelerator based operations may be pending or in mid-flight, but all of a sudden, host PCI based requests are issued, which necessarily causes the accelerator to suspend its operation and to flush out the internal graphics memory arbiter (PCI transactions must take precendence over other device memory access). So in fact, this kind of thing can really drain the performance from the accelerator's point of view. However, from the host's point of view, the direct PCI graphics RAM access is available as soon as is correctly possible (as opposed to being unecessarily pessimistically safe by waiting for all pending operations to complete as typical accelerators have done in the past), thus reducing host latency. In other words, in total, there is more busy work accomplished per cycle with this solution.
Pretty nifty idea wouldn't you say? In the past when I've presented this idea to someone in the graphics industry I've found a lot of skepticism and strange looks as if I've just showed them a three headed monster. Anyhow, having implemented precisely this, and seen performance benefits from it, I can assure you that this is not some crazed dillusional idea. It really works. Programmable solutions such as the MPACT media processor and the Rendition Verite or even the Matrox GXXX series can implement such ideas with little difficulty. Pure hardware solutions need to spin their silicon to include an operation counter, if they don't use this idea.
Finally, I need to re-iterate a feature that was only briefly mentioned above: DMA. Accelerators with "BUS-mastering" capabilities can fetch uncached host memory over the PCI or AGP bus without any hand holding from the host CPU during the transfer (i.e., using DMA). Using such a scheme for texture swapping, and other memory transfers increases the parallelism of the host with the graphics accelerator, but again there are arbitration issues (when does the host know when a DMA transfer is done?) This is covered in the discussion above. (The recently announced Permedia 3 uses host system memory like an L3 cache in its memory controller -- this allows texture downloading to happen transparently and efficiently. If only a part of the texture is needed then only that part will be DMAed from the host memory over the AGP bus.)
Features and Host Feature Emulation
These days the graphics market is being driven by: price, how well they support games, and how well they perform on benchmarks. In the very early days of PC based graphics acceleration (starting in 1989, following the footsteps of the IBM 8514) graphics acceleration was limited to 2D. But with the advent of Direct Draw and Direct 3D (originally 3DDI) and availability of 3D accelerated games (Quake) 3D has taken a front seat.
While 2D has always been very simple for graphics companies to deal with, 3D is entirely a different beast. The rendering requirements are far more complex, and the output can happen in several different modes. Fortunately, for PC vendors, around this time (from about 1994 on) many SGI employees who were very knowledgable about 3D acceleration were getting fed up with SGI's apathetic attitude towards the booming PC market (as well as some of their crazed ideas such as the purchase of Cray). This combined with the failure of many high end graphics companies (like Kubota, ShowGraphics, and Convex) meant that the expertise was readily available for hire.
Several companies (ATI, nVidia, 3DFX, Chromatic Research, Rendition) siezed this opportunity to staff up and all have since embraced 3D in a way that has turned the entire graphics market onto the 3D battlefield. The companies that failed to do so (Cirrus, TSENG and Trident for example) paid the price, and have fallen out of favor.
Anyhow, in the early days, all the basic questions about 3D were asked and various answers have seen productization. Here are a list of failures in no particular order, just to give you an idea of the painful learning process the 3D industry went through:
- nVidia NV1 (productized by Diamond as the EDGE 3D) used a special API to accelerate quadratic patches. However, it was non-standard, slow, and proprietary, all of which guaranteed its demise. (nVidia has since abandoned such ideas and have gone straight to a Direct 3D specific accelerator, emphasizing benchmarks.)
- ATI Rage 3D - although this did well in the market place, in its original incarnation it was an abysmal 3D architecture that essentially failed to properly perform perspective correction. (This didn't keep ATI from compensating by convincing Ziff-Davis to endorse this defect.)
- Virge - like the Rage, this did well in the market, but mostly because it was cheap. The 3D acceleration could not do texturing and required an inordinantly high amount of host based interaction. (S3 lost nearly a years revenue as a result of the backlash of people's disappointment with this product. They then threw their weight behind their "Savage" architecture which had some market acceptance. However, S3 has floundered as a graphics company and was recently sold to VIA.)
- Matrox Mystique - Again with no accelerated texture mapping, this architecture, primarily software rendering limited had no hope of displacing any of the true 3D accelerators. (Matrox has done a 3D redesign from scratch and introduced the G-series of accelerators that thoroughly obsoletes this previous products.)
- MPACT media processor - Totally underdesigned for 3D. Although the architecture is innovative and powerful, it is not optimized for contemporary 3D performance. (Chromatic was bought in pieces by ATI and mcc online.)
- Pyramid 3D - VLIW is not a substitute for a superscalar hardware graphics pipeline. Like the MPACT, it made it flexible enough to support radical features such as bump mapping, displacement mapping, and non-triangle primitives, but without an industry standard API, they could not sell it to anyone. (TriTech is no longer supporting the Pyramid 3D architecture. The architects of the Pyramid 3D who now call themselves "BitBoys Oy" were making another graphics architecture called Glaze3D but that appears to have slipped badly as well.)
Nowadays, everyone is converging on an nVidia RIVA 128-like architecture; a no nonsense approach that is optimized to fit the Direct 3D API perfectly. No unnecessary screwball features, and no lack of support for what Microsoft is evangelizing, for better or worse. OpenGL is still considered a second priority, but is being adopted by more and more vendors as way to support Quake, as well as keeping Microsoft in check (an important consideration these days).
Basically, 3D acclerators need to support perspective correct texture mapping to be considered a basic accelerator. However, the feature bar has been progressively raised by competition and software support requirements to include, built-in triangle setup, MIP mapping, fogging, bilinear, trilinear and anisotropic filtering, alpha blending, (edge) anti-aliasing, stippling/dithering, compressed textures and multitexture.
These features, in the common SGI-like architecture are usually all implemented as stages of a large 3D pipeline. The pipeline roughly follows:
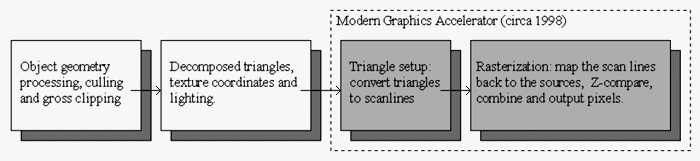
My discussions with hardware experts indicate that the path to the highest performance of the 3D pipeline degenerates to question of "throwing gates at the problem". For example, certain stages are necessarily multicycle such as the perspective correct divide. But a divide (or a very good estimation) can be performed in a handful of totally pipelined inidividual clocks. So the divide stage is turned into several partial divide stages. This increases latency while allowing a throughput of up to one pixel per clock.
Then to go beyond one pixel per cycle, multiple pipelines could be set up to calculate several pixels per clock. The most straight forward way is to simply perform an adjacent chunk of pixels in parallel. This the approach of nVidia's TNT architecture. However some vendors (3Dfx) have taken a scan line interleaved approach. This later solution is actually easier, since it can actually be split over multiple processors (and is a convenient way of further splitting the memory bandwidth), but it is a less effective use of silicon, since not all stages can or need to be duplicated. That is to say many of the duplicated gates could be re-invested in other ways to improve performance. 3DFX is often seen touting this as a good way to maintain "scalability", which provides a better short term solution for increasing 3D performance, than waiting for the company to design a new architecture. (This is why the Voodoo architecture has been able to hold the lead over RIVA, until the TNT architecture.)
Triangle setup may take several cycles of precalculation (sorting, incrementing value calculations, and limit setting) before it is able to start outputing scanlines. So, one could easily parallelize this to output scanlines at an exceedingly high rate, and to buffer the results in a scanline queue, so that the initial clocks can be hidden by overlapping with the scanlines of the previous triangle from this buffer. Such a buffer could also be useful to compensate for uncached texture source initial access times.
Finally, the brute force approach of making a larger texture cache is just one more example of how throwing gates at the problem can increase performance. Its all just a matter of the number of gates.
Missing a rendering feature usually means that software applications will simply do without such a feature which degrades quality. The combination of input from Microsoft, graphics vendors, and 3D software developers, have been raising the bar in terms of the number of features to the point where ordinary desktop PC's will soon subsume the graphics workstation market. As a rule of thumb, any simple feature that can be put in hardware should be, and software emulation is not an acceptable option from a performance point of view.
Programmable architectures such as the MPACT media processor or the Rendition Verite allow such features to be added in software even after the product has been deployed. Unfortunately, with the rather spotty adoption of these products by the market place, the benefits of such flexibility have not been realized.
Update: ATI has added various MPEG acceleration components (motion compensation and IDCT). nVidia has added stencil buffering (a cheap OpenGL based method for performing shadows or other sorts of porjections.) Matrox has added Bump mapping to their feature list. 3DFX and BitBoys will be adding accumulation buffer anti-aliasing (3DFX calls it a T-Buffer) to their feature list. ATI, 3DFX and Matrox have added TV tuner capabilities. In the high end 3DLabs has added on board transform and lighting hardware. These recent feature fan outs are representative of the level of innovation still available in the graphics market. As with 3DFX's multitexturing, though, we can imagine that all of these features will be adopted by all the vendors.
Update: nVidia and ATI have added transform and lighting as well as complex pixel shader modes to allow for per pixel bump mapping and lighting effects. 3DFX's T-buffer is now here, but has had a very luke warm reception (especially in the face of their competitors implementing software versions of the same feature.) We still await Matrox's response -- little is known about this chip.
Monitor Refresh
Finally, there is the issue of monitor refresh. As discussed in the memory bandwidth section above, it takes a certain amount of memory bandwidth away just to update the monitor. However, to avoid tearing or flickering, 3D applications, perform double buffering. That is when rendering is ping-ponged back and forth between two frame buffers, with the monitor being alternately refreshed by the buffer which is not being rendered to (the stable, displayable buffer.) For a deeper description of non-accelerated methods for dealing with flickering and double buffering see my flicker free animation page.
In any event, to repoint the monitor to refresh from a different section of graphics RAM to avoid tearing, you have to wait until the current refresh (if one is pending) is complete. Typically this is done by "waiting for vertical retrace". This "wait period", however is dictated by the specifications of your monitor, not the performance of your CPU or graphics accelerator and by those processor standards is extrememly slow (on average, 1/36th of a second on a 72Hz display mode, for example.)
Lets take a look at the path that the monitor scan gun takes:
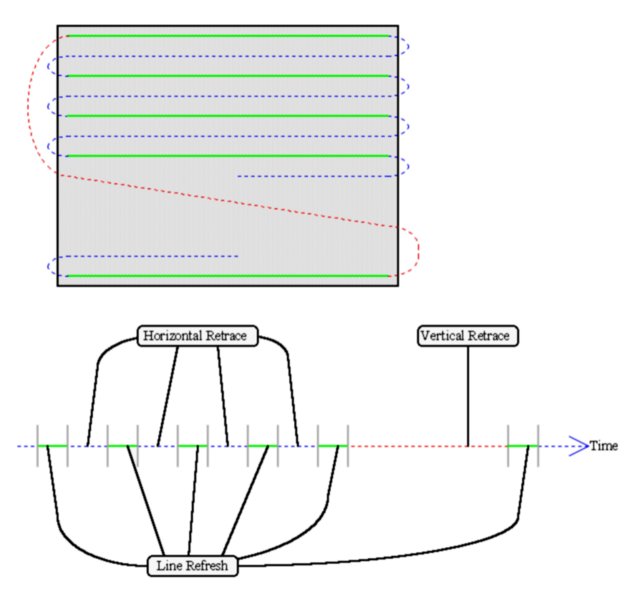
As you can see from the diagram, there are several fixed real time events that have a maximal priority (otherwise your monitor would fail to display properly). The length of each event is determined by the mode you are in which is programmed into the graphics memory digital to analogue output converter, more commonly known as the RAMDAC. The RAMDAC must have a certain amount of the display memory available to it immediately on request to perform line refreshes. Older VGA graphics cards whose memory did not have the bandwidth could not even display certain modes. Even contemporary cards run slower or not at all in high resolution (1280x1024x24bpp @72Hz for example) modes for sheer memory bandwidth reasons.
As mentioned above, VRAM was originally produced to try to solve this problem (to allow multiple simultaneous accesses) but it was expensive and clock rate limiting by virtue of its complexity. Newer solutions simply buffer memory fetches ahead into a small cache in the RAMDAC so that the line refresh data access time can be overlapped with previous RAMDAC output or horizontal retrace events. This solution is much more economical, and scalable than the VRAM solution, but to be technically correct requires a good real time sensitive ram arbitrator.
Commonly, graphics companies may not make a rigourous ram arbitrator, but instead rely on having enough memory bandwidth to service nearly any kind of real world bandwidth situtation. What happens, is that under certain (usually repeatable) circumstances (like a large bus based transactions touching the visible frame buffer) the screen may "sparkle", because it cannot access the memory needed to refresh some portions of the screen. The market decided that this is unacceptable, so graphics vendors decrease the allowable refresh rates or remove some display resolutions altogether to eliminate these visual anomolies.
Another solution used in the past was to run the monitor in an "interlaced mode". In this mode, only every other line of the mode was refreshed, alternating between even and odd "fields" on every screen refresh (NTSC televisions work this way). This halved the required bandwidth, but produced a very low quality, jittery output. The market decided that this is unacceptable, so such modes have all but disappeared.
In any event, exactly *how* you wait to perform a frame buffer flip is very important. Most graphics cards have a memory mapped register that returns the state of the analog display line, or a retrace trigger/interrupt of some kind that can be probed by the host. So the simple way of doing this is to simply wait for the command queue to empty then wait on the host for the scan beam to hit the bottom of the screen, then perform the display flip (repoint the display start address to the other frame buffer.) This has no effect on the the render speed if the graphics card can render at a rate that is at least the speed of the monitor's refresh, but as of today's technology (1998), that is not usually acheivable, and higher resolutions still leave a lot of room for performance sensitivity.
This is such a big deal that it motivated Ziff-Davis to twice (3D WinBench and their new pure application based benchmark) evangelize disabling of such synchronization for the purposes of benchmarking. These things make me sick. What Ziff-Davis, and perhaps the many graphics card vendors who pressured them to do this don't seem to realize is that this bottleneck, like any other that I have encountered, can be attacked inexpensively with the right architecture.
Anyhow, the big idea here, of course is to eliminate the "wait for retrace". There are a few strategies that I've outlined relative to a single example here (MS-Word DOC; StarOffice may be used to view it.) Essentially by doing the flip as close to the Ramdac as possible, the time spent waiting for execution resources is minimized. There is also essentially no cost for any of the solutions described.
Finally, to avoid all waiting penalties altogether in the SGI-like architecture, the graphics card must induce a triple buffering mode as described in my flicker free animation page. This is certainly not the most desirable situation since dedicating graphics memory for textures will usually lead to greater overall performance.
Of course, its not exactly all that helpful if the graphics vendors are idiots (read: nVidia.) The typical mistake when implementing a triple buffering scheme is that once both back buffers have been filled, rendering is again stalled until the front buffer is done displaying, and can flip with the older of the two back buffers => thus always proceeding in an oriented deterministic order. This incorrect implementation only pushes out the stalling situation instead of solving it (and it leads people to incorrectly believe that they may need to go to quadruple, quintiple, sextuple etc buffering in the future.)
The correct implementation implementation simply observes that there are only 4 display buffer types: (1) Currently being displayed, (2) Currently being rendered to, (3) Completed, but not yet displayed, and (4) Obsolete or empty. Basically, at the display pointer should be updated to point to the newest buffer of type (3), and relabel the old buffer as type (4). At the time of picking a new buffer to render two a type (4) or the oldest buffer of type (3) should be chosen, and the completed buffer should be relabelled as type (3). Using these rules there is never a reason for either the accelerator or the host to stall.
That's about all the opportunities for covering up the wait for retrace delay
for standard SGI-like architectures. However, deferred renderers open up even
more opportunities, that will be discussed in the architecture section.
| Benchmarks |
3D WinBench
In the popular benchmark 3D WinBench, the score decreases for omitting features. 3D WinBench is the primary measure by which PC OEMs who are not otherwise knowledgable about 3D decide how good an accelerator is. This has lead to some very unfortunate market trends. The Intel i740 and MPACT 2 media processor took advantage of this check box granularity by simply supporting (nearly) every feature tested by 3D WinBench. This gives an inflated score relative to the actual performance of the graphics accelerator (and it did not matter much as the the leaders, nVidia and 3Dfx still managed to pull away in the 3D WinBench score war.) The score is simply summed over the scores for each features subset tested.
There was also some controversy over an early ATI Rage product which did a horrible quadratic approximation to perspective correction; while ZD's test said that this product should fail one of the tests (and thus score significantly slower) ZD actually backed this crap. This was totally ridiculous considering that every one of their competitors was doing pixel accurate perspective correction (except possibly nVidia whose low precision RIVA 128 pipeline could produce displacement errors causing polygon edge cracking.)
The 3D WinBench program itself has several problems with it as a benchmark. The primarily problem is that it does not measure the performance under real world situations. In particular, although it allocates a back buffer, it actually only renders to the front buffer, and never flips between the front and back buffer between frames. Nearly every graphics OEM has been forced to implement "the obvious cheat" whereby the back buffer memory is illegally recycled for use by textures to avoid texture swapping with main memory. Heck, even if a graphics company wanted to do this correctly, they could use a method known as "lazy update" where the back buffer allocation isn't even made until the first rendering operation is performed on it. This has no real world benefit; it is strictly a 3D WinBench cheat.
Also since no vertical retrace synching is performed, it is not inconceivable that in situations were the accelerator can update a frame faster than the monitor can refresh a certain kind of speculative rendering where only the portion of the front buffer which will actually be visible, in real time is actually rendered (this can be done via clever use of clipping.) I am not aware of any accelerator that does this. Similarly, simple frame skipping achieves substantially the same kinds of unrealistic kinds of performance improvements. The quality of 3D WinBench's output is so bad even when supported properly (simply due to tearing) there is no visual way of detecting such a cheat.
Quality tests are also kept seperate from combined tests, so within the drivers it is also possible to detect the situation and use lower resolution textures in the combined test to decrease memory bandwidth utilization.
So in the end, in order to sell their graphics card, graphics vendors have been forced to implement some of these cheats which are usually turned off during the run of real world applications. Things like the frame counters in actual games have become more credible benchmarks. Unfortunately, Ziff-Davis is overly motivated to evangelizing their nonsensical 3D benchmark. It has had the effect of propping up crappy solutions from Intel and ATI, and not differentiating real world game performance (between the 3Dfx and RIVA products for example; although they score fairly closely, the 3Dfx product is usually significantly faster in the frame counters of most games.)
Does this sort of cheating seem far fetched to you? Take a look at the circumstances. All of these cheats can be performed without actually detrimental side effects in real games because it is so damn easy to detect WinBench behaviorially (allocates back buffer, draws to front buffer, does not perform flips). This means the driver can easily go into a seperate WinBench Mode. PC OEMs such as Dell simply don't have the expertise to understand how good a graphics solution really is. So they rely on 3D WinBench, because PC Magazine, and PC Week evangelize it. A deal with a popular PC OEM can be worth hundreds of millions of dollars. Sacrificing moral correctness is easy to rationalize in the face of that kind of money.
Make no mistake, even graphics vendors that have made public statements to effect of the correctness of their solution have implemented some of these cheats. There is simply too much money at stake, and its the only way to keep up with the competition.
Note: Another "cheat" is the idea of auto-MIPification. This is where non-MIP mapped textures are pre-processed to be MIP mapped (MIP-mapped textures tend to perform better due to better memory locality). But the truth is, I hestitate to call this a "cheat". I like to consider it more like a work around for developer ignorance. The fact is, if MIP-mapping is available, software should always use it. In general it increases the performance and the quality of the output. (Though some backwards architectures have had performance problems with MIP mapping.)
But the controversy doesn't end there. When it comes to the quality issues, the Ziff-Davis people in their very own magazines have made startlingly bad judgements. The RIVA 128 has an unusually low precision perspective correction process which leads to "cracks" between triangles. Yet these anomolies are never mentioned and have no negative impact on their score. When ATI implemented perspective correction with a bad quadratic approximation while everyone else was using the much more accurate Newton's method, Ziff-Davis let it slide, and did not penalize them for improper perspective correction. Incidentally, ATI and Gateway (which uses ATI an aweful lot) pay for a lot of add space in PC Magazine.
Update: I recently heard a rumor (from a reliable source) that nVidia actually authored one of the tests in 3D Winbench!!!! (The chambre scene.) Holy crap!!!! Talk about biasing a test! I mean, there is no excuse for that kind of shenanigance. Nobody should use 3D Winbench for 3D graphics testing purposes.
3DMark
This is a relatively new 3D benchmark that has been developed by the people at Futuremark/Remedy. I recently visited these folks to perform some optimization work for this test. I must say that these guys are remarkably unbiased, and have bent over backwards to make sure that there test is both fair and comprehensive. The test itself is an amazing piece of work. These folks have had to deal with some of the anomolies the people complained about with their older benchmark (Final Reality), but with the latest 3DMark, they seemed to have really done their homework. The internals of 3DMark is based on a game engine that is being used an actual game -- Max Payne that will be available in less than a year's time.
They have had feedback from graphics vendors, cpu vendors, and most importantly game software developers that have shaped 3DMark into what it is today. Cheating with 3DMark will not be so easy, since it is basically a game simulation test. Anything that a vendor does to speed it up should reflect in real world situations as well. It has already garnered rave reviews from numerous sources.
To give you an idea of how much people will need to respect this test, it is now known that AMD's 3DNow! as well as Intel's SSE instruction extensions have been used in the engine to ensure that absolutely the most optimistic testing conditions are always being used.
I hope and expect that this benchmark will supplant 3D Winbench. The FutureMark crew, definately have a great deal of integrity, unlike their Ziff-Davis counter parts. It is quite simply a better benchmark. Graphics vendors will need to heed this test (most are already very aware of it.)
2D WinBench
As a comparison to 3D WinBench, 2D WinBench is much more realistic test. 2D WinBench takes a simulation of applications running, extracts only the GUI rendering commands and plays them back at high speed. In principal this is good because it measures the performance of the GUI which every Windows application uses.
But 2D WinBench also has its share problems, and like its 3D counter part, it makes the test equally ridiculous.
First of all, the amount of architectural work put into 2D acceleration for the past 8 or 9 years is enormous. We are now at the point where the faster 2D cards can update each pixel of a 1600x1200x24bpp screen at a rate of at least 70 fps. All the overhead of reducing low level primitives to something that the accelerator can digest has turned to a truly trivial performance hit. In realistic situations there is basically nobody complaining about the performance of any modern accelerator card just because the gui is running too slowly.
Modern graphics companies concerned about 2D performance basically take something called a NULL driver (a graphics driver than accepts the low level rendering commands but does no rendering work whatsoever) and see how close they can come to its performance. Companies like Matrox are basically almost at the NULL driver's performance in all situations. (Though I'd like to congratulate 3DFX for getting a Matrox-like performing 2D card in only their second attempt -- the Banshee)
For 2D considerations in the real world there are only two kinds of accelerators: acceptable (i.e., does all basic high frequency 2D accelerations, and has high graphics memory bandwidth) and unacceptable (otherwise obsolete, missing huge amounts of functionality, insufficient graphics memory, etc). Even $35 previous generation 2D graphics accelerators bring enough performance to make the whole thing a non-issue.
Given the above premise, if one is concerned about measuring the graphics performance of a system, then shouldn't they find applications that are totally bottlenecked by graphics performance like AVI/video playback and capture? Even though the test does measure Corel Draw performance, my own investigation shows that the resulting partial results has an almost zero weight in the overall score of 2D WinBench. CAD/CAM programs are part of a seperate "High End Graphics WinMark" test that few people quote.
Anyhow, the remaining interesting bottleneck of transfers between host and graphics memory is actually subtracted out of the intermediate results! I'm sure their reasoning was that this was just measuring PCI bandwidth, but they failed to consider the possiblity of deferred or asynchronous (DMA) transfer. They also failed to consider the latency and associated architectural considerations described above in the Host, accelerator communication section.
For example a host to video memory transfer can be sped up by immediately copying from the host to another locked uncached host buffer, then a command can be posted to the graphics accelerated queue to perform a bus master read to transfer the memory when the accelerator has completed its other pending operations. Such a solution would remove the apparent latency of a host to graphics accelerator even if the accelerator is very busy. But of course, if WinBench doesn't measure the performance gain, then graphics vendors will not feel motivated to implement such functionality.
Anyhow, now that 2D WinBench has become, for all intents and purposes a test
about splitting hairs, don't you think it should disappear? Intel doesn't!
Why? Because all that's left to measure is CPU overhead for processing high
level primitive to low level primitive decomposition (GDI, and to some extent
other portions of the Windows kernel.) So you end up with a test whose
largest determining score factor is the speed of the underlying CPU. In other
words the message being sent to consumers is that to get the fastest 2D
graphics performance you need a fast CPU. The message that 2D performance is
essentially a solved problem is completely lost.
| Architectures |
When considering different architectures for a graphics accelerators there are some obvious competing factors:
- Cost of development
- Performance
- Compability
- Features
For now, since the emphasis is on 3D, we will ignore the Features aspect. Such things would include MPEG playback assist, TV out, multi-monitor and so on. None of these has had a major impact on the architecture.
With an eye on the top three from above then, we will consider the following architectures.
- Ordinary SGI-like graphics pipeline
- Deferred renderers
- Programmable architectures
- Talisman
With the exception of PowerVR, all the shipping PC graphics accelerator cards (as of 1998) use an SGI-like graphics pipline. This is the pipeline where triangles are mapped to textures in projective space one at a time rasterized into pixels whose z-values are compared and written to a screen sized Z-buffer, and final color values are composed out of a simple equations involving a fixed number of sources and written to a single resultant destination. The triangles are, for all intents and purposes, rendered iteratively in the order in which they are recieved in a total fire and forget based strategy.
The SGI-like architecture has a lot of history and is well understood by many people (in particular, its well understood by the droves of ex-SGI employees that are now working for other graphics companies.) The architecture is also extensible to include radical departures such as video textures, or non-triangular primitives as the market decides its ready for more 3D capabilities.
The cost is minimal since the industry has the most experience with this. The pipeline stages are fairly straight forward, and the software infrastructure naturally supports this method.
The performance curve of the current leaders (nVidia and 3DFX) indicate the performance is doubling roughly every 9 months with no end in sight for increasing levels of performance. Both 3DFX's Voodoo3 and nVidia's TNT Ultra are demonstrating unheard of levels of performance. Both are host driver limited in current benchmarks.
In terms of compatibility, this is the pervailing assumed architecture so backward compatibility is most easily achieved through API drivers.
Deferred renderers
Stellar Graphics, Raycer, GigaPixel, PowerVR, Trident (and at least two other companies which I cannot mention because of NDA agreements) have all embraced the idea of a chunk based, or deferred rendering scheme. The idea is that all the triangles for a scene are first stored in an array (before any pixels are drawn) and then the screen is decomposed into a grid of rectangular chunks that are then sequentially rendered from top to bottom.
What is the advantage of this? Primarily it allows reuse of the Z-buffer allocated to each chunk. In fact, to get the most out of this, the Z-buffer should simply be part of a chip local memory arrary (like a cache or SRAM -- Stellar's PixelSquirt architecture decomposes all the way down to scan lines and pixels, so they only need one entry Z-buffer, for each pixel pipeline which is typically 1 or 2 wide.) So the Z-buffer memory bandwidth and data occupation magically turns to zero. As an added bonus the output memory bandwidth becomes proportional to the size of the screen which you would expect to be less than the SGI-like architecture because there is no overdraw. Keeping this in mind, full screen super-sampling (otherwise known as full screen anti-aliasing) becomes a relatively minor performance hit.
But of course, it gets better. Since the memory bandwith has been so radically reduced, the overall performance becomes more related to the architecture of the graphics controller, than the memory bandwidth. This gives better scalability via ordinary frequency increases in the controller itself.
Isn't that cool? So what are the disadvantages? Well, it requires that Z-buffered triangles are the only drawing primitive used. With the SGI-like architecture you can play tricky games with non-Z buffered 2D decals rendering in mid-scene, although there is no evidence that software writers currently do or will exploit such an idea. There are also issues with rendering order and alpha blending.
The defferal time is necessarily long and thus you may end up in situations of under utilitzation of the graphics hardware followed by high utilization in ways that make it difficult to take maximal advantage of parallelization without introducing visual latencies (by as much as two frame flips.)
The potentially random and unbounded number of triangles means that specific graphics hardware will not be able handle all situations by itself. This pretty much requires CPU assistance, in ways not required by the SGI-like architecture.
There is a sorting algorithm required for quick chunking of trivial sub-rectangles (this is especially important for correct alpha blending as well). Again, because the number of triangles may grow arbitrarily, some sort of CPU assistance will be required. (But it has given software engineers a new opportunity to try to flex their brain muscles; a flurry of patents have been filed for this alone.)
I made mention of a possible "wait for retrace" optimization available to defferred renderers above. While I don't know of a specific architecture that has actually addressed this (though I very strongly believe that Stellar's PixelSquirt has done this), my opinion is that because of the deterministic rendering order, there is an opportunity for the rendering to "chase the scan beam". That is, rendering into the front buffer can start before the beam enters "vertical retrace" state, if a back buffer is already complete so long as it is arbitrated with the current scan beam location, before a flip to back buffer is performed. Since the pixel rendering can be ordered with respect to the scan line, that means that front buffer can be incrementally rendered to before it is even finished displaying. Its not quite as perfect as triple buffering, i.e., in the worst case there is still stalling but only if the graphics accelerator rendering rate is well ahead of the screen refresh rate.
Employees from 3Dfx have been observed saying things like "We hope everyone else in the industry moves to chunk based rendering". Such a comment may be backed by the fact that the host assistance required for deferred rendering, while theoretically could be small, it cannot easily be removed. So in terms of a maximal ceiling, a sufficiently high performance SGI-like solution (i.e., if the memory bandwidth problem were "solved" in some other way) could, in theory, beat all defferred rendering implementations. (There is at least one company, that again, I cannot reveal because of NDA, that is working on a highly aggressive memory architecture that may indeed make the deferred rendering architecture impotent.)
ATI has appeared to have declared their position on the situation. The Rage128 architecture is a SGI-like architecture that has attacked the memory bandwidth problem by attaching a frame buffer cache (for the accelerator, not for host communications over the PCI bus). Of course the biggest advantage it offers is to address the bandwidth latency of redundant accesses, which are certainly not trivial (think about rendering a 3D object made of many triangles.) Taken to the extreme, this sort of approach can match the bulk of the advantages of the deferred rendering technique (defferred rendering still has better trivial reject possibilities, and can attack the wait for refresh problem in ways still not available to the SGI-like architecture).
The cost of this architecture is very high because there are new stages, and new problems that need to be solved. This rendering scheme does not have nearly the momentum behind it that the conventional SGI-like architecture does.
The potential performance of the deferred rendering scheme is likely to totally shatter any kind of SGI-like architecture especially for increasing levels of content (such as Quake 3 or Max Payne). Such an architecture could, if the host can keep up, allow us to leave polygonal objects behind us, and start looking to Nurbs as the object rendering primitive of choice. It would also allow us to play our games at 1600x1200x32bpp.
Strange things like "texture renaming" may be necessary just to maintain compatibility with the SGI-like compatible content. (For example, suppose you load texture A, render from texture A, overwrite texture A with some other content and render from texture A once again -- the deferred renderer will need both copies of texture A, since the entire texel and texture list is required.)
Programmable architectures
There have been many attempts to bring programmable architectures to market as 3D accelerators. These including 3DR (as well as many other purely software based 3D rendering schemes), the MPACT 2 media processor, Pyramid 3D, and the Rendition Verite.
It should not surprise anyone to learn that the more hardwarish the solution, the more industry acceptance it has recieved. :o) 3DR was laughable from the very beginning, Pyramid achieved lack luster performance and did not sign on anyone willing to sell it, the MPACT 2 (which has a partial 3D pipeline) simply did not sell enough to gain critical mass, and Rendition (which has a totally seperate 3D pipeline and RISC core) has had the misfortune of mistiming its products against the market leaders (ATI, and nVidia.)
Of these companies, only Rendition shows solid long term viability. So does this mean that programmability is a bad thing? No, absolutely not. In fact the Rendition solution is probably ideal since it has the best of both worlds. It is extremely flexible because of its tiny RISC core and totally uninhibited in terms of performance since it has a totally seperate complete 3D pipeline where the bulk of the silicon is dedicated.
The problem with the MPACT media processor is that it is not focused as being a 3D part at all. The flexibility was put to use to enable features such as MPEG decoding, a modem and probably the most advanced commodity audio card in the industry at the time (5-6 megs of audio RAM and all system RAM available to substitute for ROM audio samples!) But unfortunately, the market demanded that it be sold as a 3D card with some extra features. Having mediocre 3D performance by conscious design certainly didn't help its case.
I don't know much about the Pyramid 3D other than that it was a generally programmable 4-instruction wide VLIW processor. My best knowledge is that the performance was disappointing. So it was like the MPACT, only worse. :o)
So why did I mention 3DR? Simple. There are people inside Intel that are still under the dillusion that the future of graphics rendering will eventually fall to general microprocessors. I have the good fortune of knowing a little about the architectures of both graphics accelerators and CPUs. Quite simply, neither is suitable to taking over the job of the other. They solve their performance problems in totally different specific ways.
To give you a good idea of just how bad Intel is at trying to design their own solutions for graphics take a look at their attempts so far: i860, 3DR, MMX, and AGP. Each was positioned as a graphics enabling technology (in the past, attempts were made to turn the i860 into a graphics accelerator) and none has delivered any credible improvement in graphics performance. (The i740 is a Lockheed-Martin design spliced together with a Chips and Technology 2D part, that had little or no technological input, besides fabrication and AGP, from Intel.)
Even though AGP looks good on paper (most people even in the graphics industry believed that this would be an improvement, at least for high resolution, or highly textured scenes), there is not a single credible benchmark available out there that shows any significant difference between AGP and PCI graphics solutions for the equivalent graphics accelerators. (Update: This is no longer true, 3DMark 99 has a specific test for very large textures that pretty much degenerates to an AGP test -- though their base benchmark scores are not generated from this test.) It should surprise nobody that the i740 simply does not support PCI (otherwise the comparison between PCI and AGP solutions might be too embarassing for Intel to live with.)
What of MMX? What can I say? If you try to use it to accelerate pixel
output with it, you would be doing so on the wrong side of the PCI
bus. It would be like trying to cut down trees on earth by mounting a
big laser on the moon; its a horrendously retarded idea. What about geometry?
Well, you need floating point functionality, and MMX is a floating
point decelerator, in case you didn't know. To tell you the truth
3DNOW! looked like more of an intrusion into 3D acceleration, until I
investigated it further. (Its adds to, but does not replace 3D acceleration,
by accelerating stages just above the setup and rasterization stages.)
|
Transform and Lighting
As long as I've brought up 3DNow! we might as well talk about transform and lighting. For now, that remains the domain of the CPU. 3DNow!, AMD's technology for high performance 32 bit SIMD floating point engine in their K6-2 and K6-3 processors has helped raise the performance bar, by reducing CPU overhead of this stage. Up until now geometry and lighting has remained in the domain of the CPU. But as with other stages of the graphics pipeline, graphics hardware designers have been eyeing it as a performance boosting opportunity. The idea would be to bring a massively parallel floating point engine that might perform a one cycle throughput 4x4 matrix multiply, for example. Such an idea has the obvious benefit of once again bringing more parallelism to the graphics pipeline, and certainly if the accelerator can keep the setup engine busy with its transform and lighting engine then this is practically a done deal. But there is one problem. Such an engine is likely to require a non-trivial amount of silicon, which may in turn limit the yield or clock rate of the graphics part. At the same time with the rising levels of performance seen in modern CPUs, we may eventually see CPUs that can perform the transform and lighting calculations in parallel with the time taken to perform the BUS transactions to get the results over to the graphics card. The war over who owns this stage of the rendering pipeline is about to get very interesting. In the short term, I don't see graphic vendors beating 3DNow! or the up coming SSE instructions (from Intel) or even Motorola's AltiVec but long term, architectural considerations suggest that graphics vendors should eventually take over this functionality. (The parallelism alone might make it worth while.) Among the graphics vendors looking at implementing this stage of the pipeline, is 3DLabs with its PerMedia parts. (There are at least two other graphics vendors that I cannot reveal because of NDAs, in addition to rumors that 3DFX is looking very closely at this idea. Update one of those companies is nVidia -- it is likely that most graphics vendors will now start considering adding this stage to their architecture, just in time for the Pentium-!!! to drop down to consumer level prices). Update: on 08/31/99 nVidia announced the gForce 256 accelerator which contains a transform lighting engine that they claim performs 50 GFLOPS. (A 650Mhz AMD Athlon is capable of 2.6 GFLOPs.) That's a rather extrordinary amount of floating point power. Ok, knowing that that the gForce is a 120Mhz part, that says that part is doing about 400 floating point operations per clock. Hmmm ... lets see ... a typical transform matrix multiplied by a vector is 12 multiplies and 12 adds, (24 ops). Looking at a graphics engine source that I happen to have lying around, it looks like lighting takes about 25 operations. Multiply that by 4 for a the 4 pixel pipeline (200 ops) and we are still off by a factor of two. Assuming a pipeline similar to the AMD K6 (which is capable of 2 cycle floating point operations) we see that they must be counting pipeline stages in their overall figures. In any event, it looks like the gForce is making geometry essentially a "free" operation. I must say I am impressed. |
The cost of this architecture varies with the approach. 3DR was probably pretty cheap to put together (since it was not very ambitious) however putting the MPACT together was a monumental task. Rendition was probably not too difficult either since they went with an off the shelf RISC chip for their programmability (the MIPS cpu.)
There is so far nothing that indicates that the programmability of an architecture in any way helps the overall performance of the architecture. (Although it seems as though it should be possible for the Rendition architecture to do some preprocessing of the input command list to remove redundancies not seen at the host level -- if there are any.)
So long as a basic SGI-like architecture exists, programmability should in no way hinder compatibility with the modern infrastructure.
Talisman
Talisman was Microsoft's aborted attempt at a radically new way of rendering graphics that came straight from their relatively young research arm. It was a combination of abstractions that allowed aynchronous compositions of multiple sources combined by arbitrary on the fly transformations. In this way memory for an actual frame buffer could actually be optional. The details of the architecture were only revealed to a handful of vendors who signed up to building hardware acceleration for it.
Unfortunately for Microsoft, that turned out to be only Trident. Although in theory programmable architectures such as the MPACT and Verite (or derivatives of them) could likely have supported Talisman fully, neither Chromatic Research nor Rendition signed on. Microsoft has since stopped further development of Talisman, and has migrated some of its simpler features into Direct X 7.0.
If this shows anything its that Microsoft alone does not dictate the direction of graphics and that not even they have enough clout to evangelize an idea that is too weird.
The cost of this architecture is very high. Prohibitively high. It is centered around a rendering architecture which itself may be lossy (in terms of quality.) Much of what this architecture is all about would be the subject of some research. I supposed it would have given Microsoft's research arm something to do. But this alone was enough keep graphics hardware developers away.
Of course there we great claims about the performance. However it was centered around bottlenecks at the time. The idea was to reduce the amount of "similar rendering" in the same way that JPEG and MPEG unifies "similar color values along a color wave". However, what Microsoft failed to predict was the amazing level of performance of the SGI-like architecture available today. How fast an accelerator can draw triangles is becoming an increasingly trivial problem.
The compatibility of Talisman is also non-existent. The very architecture itself requires content to be authored specifically for the very odd features of Talisman.
The future
For this segment let me get out my crystal ball and say this: inevitably, I believe we will see a graphics part with a highly splined, or otherwise parallel memory sub-system combined with deferred rendering techniques combined with a massively parallel transform and lighting engine integrated with one of the PC's chipsets. Why? Simply because such a part, in theory, could eventually (perhaps at 0.18 micron or smaller) be made cheaply, and that if properly executed would be very fast, and very compelling.
I believe that among the graphics companies that survive in the next few years, the top parts will all be chasing this design.
But there are other problems that will need, perhaps another look at the modern 3D architecture.
- SGI has demonstrated that there are plenty of opportunities to optimize
programs at the scene-graph layer. This has lead them to enter into a joint
project with Microsoft called "Fahrenheit", which will unify the graphics
architectures of OpenGL, Direct3D as well as adding a scene-graph
architecture. There are mixed feelings about this. The booming game
industry's programmers will be reluctant to buy into someone else's higher
level graphics architecture.
- Advanced features like bump/displacement mapping, and nurbs are the next
level of graphics realism that will have to make graphics vendors think about
how to implement non-triangular primitives.
- I've had discussions with people that suggest that an accelerator for
Pixar's Renderman architecture is possible. (This is the
technology that brought Toy Story and A Bug's
Life to the silver screen.) The basic idea is to describe object
surfaces programmatically by both perturbation and texture content with
subroutines called shaders. Renderman is probably the most
advanced rendering system today, but cannot be done in real time with today's
technology because of the enormous compute power needed.
Although real time raytracing is not in the forseeable future, we are fast
looking into that avenue to find the missing features in our conventional
rendering models. Radiosity lighting, motion blur, and programmatic
rendering are some of the things that through one hack or another will
eventually need to be added to feed the need for greater levels of realism.
| APIs |
There are currently a handful of viable alternatives which give you across the board coverage (or a reasonable subset):
- Windows' Direct Draw
- OpenGL
- Surrender
- Power Render (from Egeter software; very new)
- SciTech's MGL and VBE/AF (MGL is now free!)
- FastGraph (been around for a while, but try not to be taken by their propaganda)
- Simple Direct Media (OpenSource)
I would like to make a special note about Surrender. Although, I have not tried it myself, it appears to be ramping up very quickly. In the span of a month or two they picked up Rendition, Pyramid 3D, and PowerVR support, on top of the 3DFX and Matrox that I originally saw from them. I think these folks might be worth watching closely.
Other alternatives such as the Quake, Unreal, and MAX-FX engines can also be used under licensing terms. If you have the resources, you might like to consider these "completed" engines to reduce your time to market. You'll need to contact the specific vendors (id, EPIC, Remedy entertainment) to get access to these engines of course.
Update: I took a trip out to Finland, where I had the good fortune of meeting the Surrender team. What I can say about them is that they have all the neccessary amount of 3D, and processor intellectual resources coupled with a complete unbiasedness about the platforms they use. Their company is very serious and they have some mighty plans for their interface. I've seen their technology in action and indeed it is very usable.
One well known developer that is using it said something to the effect of "I'll sign my name to any quote you want from me for your product". If you are a company that needs a compelling graphics solution and quick I would definitely recommend them.
Proprietary interfaces
One of the reasons that developers have not pursued direct programming of accelerators, is that they are complicated I/O register based APIs that the creators general do not publish. With the advent of the Linux operating system, however, this has changed for the better. I don't have a comprehensive list, however, ATI, S3, nVidia and 3DFX have all had Linux XFree86 drivers written for them.
Here are the links I have on hand:
Examining the specification above shows you yet another reason why hardware vendors ordinarily don't want to publish their specifications. As can be clearly seen on page 72, they use an "Idle whole accelerator" approach (as opposed to a scoreboarding approach such as I have described above) which itself has a bug. A NOP command must be written to the queue before attempting to idle it. This likely because the accelerator dequeues commands before they are completed (its a cheap way to make an additional entry available on average -- but as can be seen its not very robust.)
| Links |
- State of 3D
- MadOnion makers of 3DMark -- the gamer's benchmark.
- Glossary of 3D Terms
- x86 CPU vendors anxious to hold onto advantages of CPU based geometry
- 3DFX technology summit (Sheesh! You'd think that someone would have leaked the "T-Buffer" stuff several months ago when it was first released under NDA ... ;) )
- The BitBoys talk about embedded DRAM and graphics cores
- Bump mapping explained (on Tweak 3D)
- Some dufus talks about a plausible hybrid tiled architecture


